



Our solutions
Find out more about how Dictate.IT’s speech recognition dictation solutions can save time in your healthcare setting
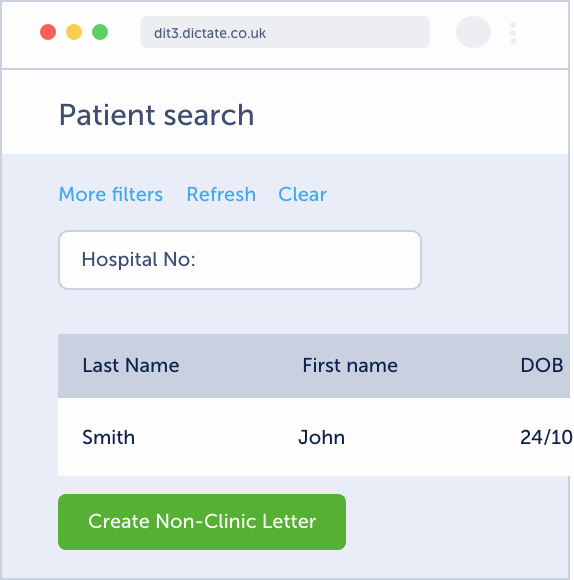
Primary care
Allowing the relocation of time for other responsibilities
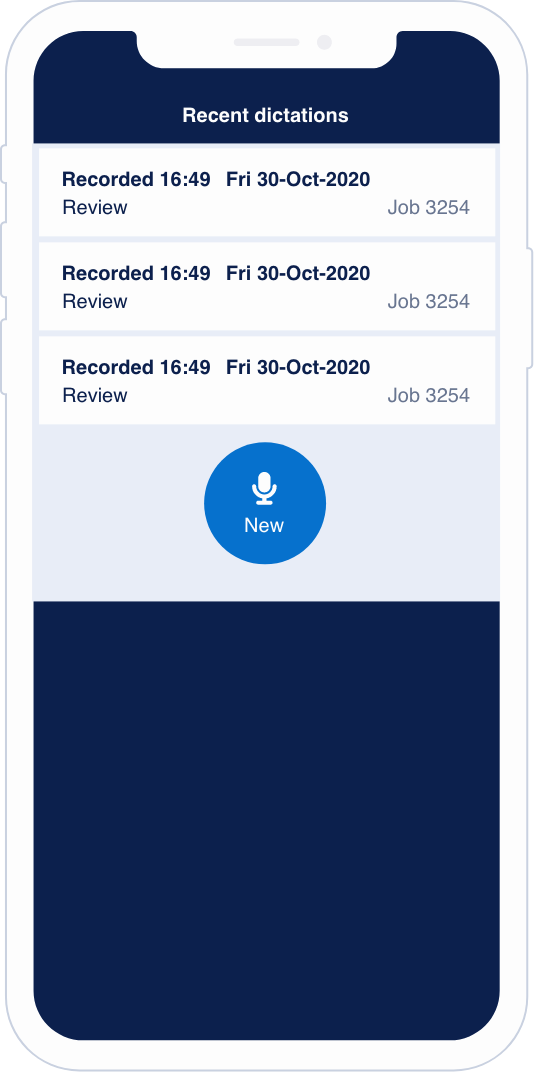
- Patient notes
- Letter production
- Patient communication
Secondary care
Maintain high standards of patient care
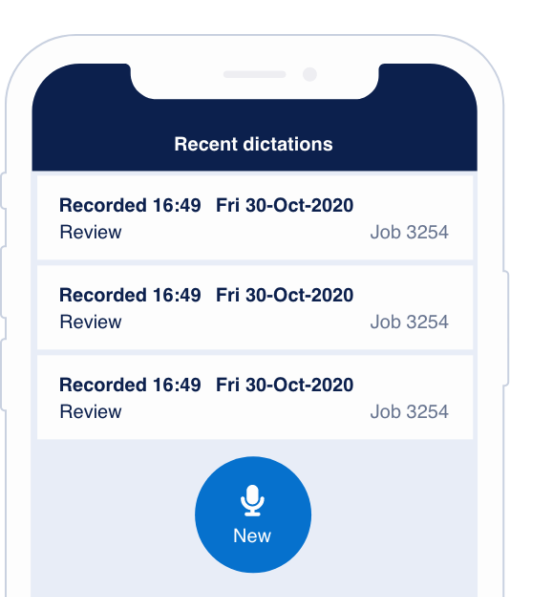
- Retain existing individual workflow
- Remote working at the point of need
- Eliminate backlogs
Don’t just take our word for it
This is what our community says about us. Organisations across all healthcare settings use Dictate.IT solutions to ease administrative burden.